Zero Trust has been with us for the best part of a decade – since the likes of the Jericho Forum, Google’s Beyond Corp and ex-Forrester analyst John Kindervag all promoted a view of moving the concept of “trust” from a location to a concept based on the identity, device and associated context.
Version 2.0 of the US Department of Defence Zero Trust Reference Architecture has been cleared for public release and is a good, detailed read regarding an actual migration and implementation model. The document is available here.
A few comments.
The word identity appears 94 times! A great relief in my opinion, that identity is being seen as key enabler of modern network and data security. That may seem obvious to many, alas it has taken several years for this linkage to become a normal part of the enterprise architecture and security solution architecture approach.
The main premise is that of the “information enterprise” and the protection of data. Many solution lead approaches to modern security can often be quite focused – protection of the end point device, the perimeter or specific API. Ultimately though, data is the king. All tasks and events ultimately result in data access or alteration. Data protection is the main goal.
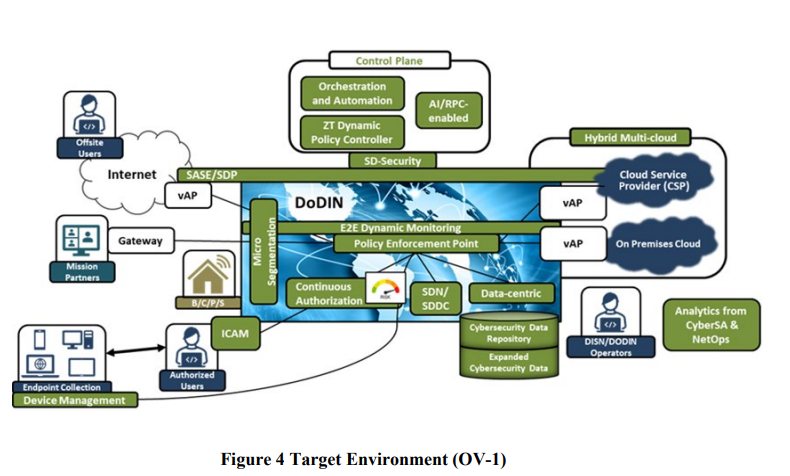
The overall target environment contains some interesting identity related components – continuous authorization, the more traditional concept of a policy enforcement point, a centralised and externalised policy controller and the main overarching idea that both subjects and the objects being accessed will be highly distributed and hybrid in deployment. The monitoring aspect in anything that uses the word “continuous” becomes hugely important.
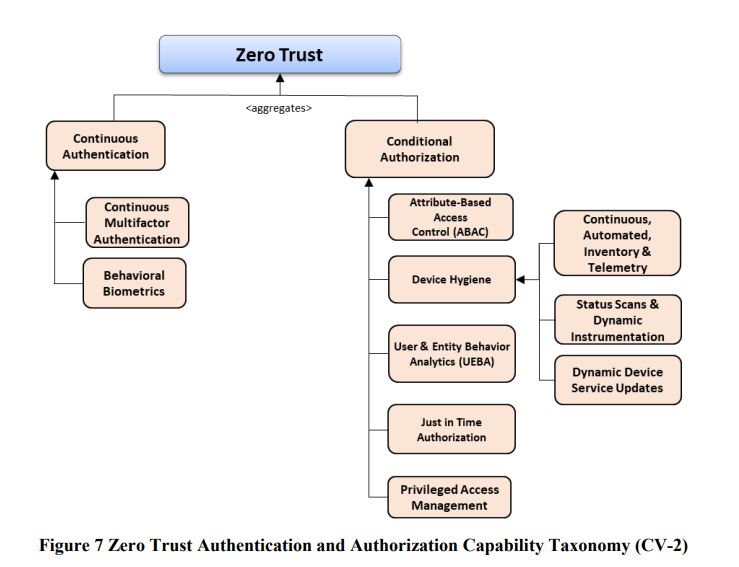
The authN and authZ capability taxonomy provides some interesting items. “Continuous” authentication can only really be achieved either via a stateless approach to request processing, or an ability to monitor behaviour. From an authZ perspective, little intrigued as to seeing PAM in this branch. ABAC is a standard model, with “just in time” concepts starting to become mainstream in COTS authorization products – a concept taken from the PAM world, which may explain why PAM sits under authorization.
The document has a good degree of comment for NPE – non-person-entities – where services, machines, RPA and other inanimate entities are engaging. The rise of APIs and automation is driving a mature model for handling the use of identifiers, uniquely issued credentials, authentication and authorization services, all in a DevOps like ecosystem, with strong bootstrapping and revocation.
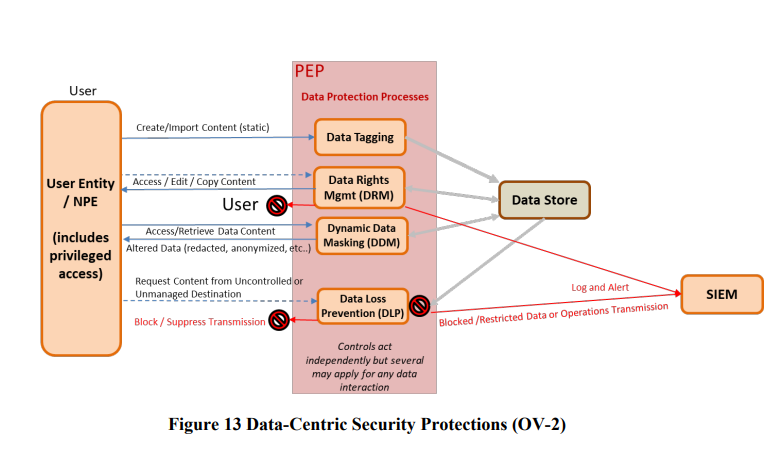

The data security protection angle is powerful – yet has a lot of moving parts. The ability to leverage DDM capabilities with redaction is good.
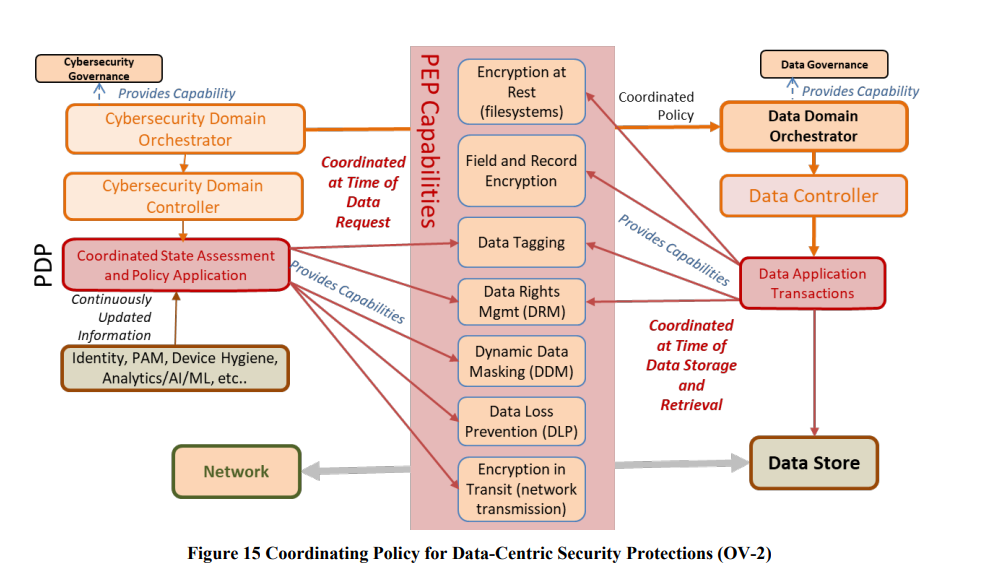
Centralised policy management in the control plane allows for scale, governance and the ability to have different stakeholders have visibility over the control logic. However, the main question arises, around how to get that policy data into the hands of the PEP – enforcement point? Do PEP’s have to call out centrally? That is time consuming, introduces latency and makes PDP’s a bottleneck and target. Do you then use a push/pull model where policy data is locally stored (or partially stored) closer to the PEPs? That causes a lot of data on the network – which may result in duplication and stale data. What about caching of decisions? Should PEP’s have that or always be stateless?
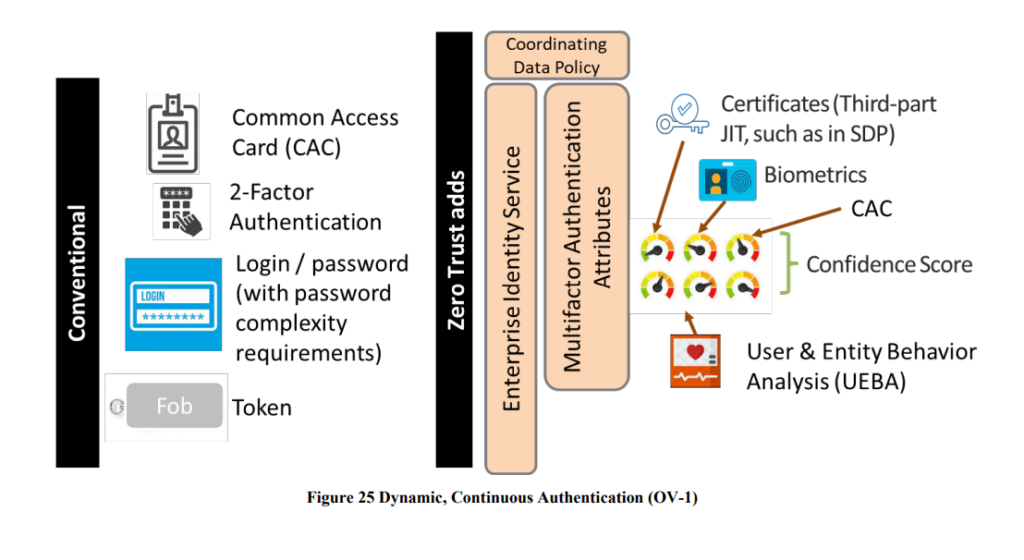
The topic of “continuous and dynamic” authentication is worth additional comment. The terms seem to be used interchangeably without really referencing the implementation. Authentication using a dynamic scheme is typically related to the use of a freshness mechanism (aka nonce, counter, timestamp) to prevent replay. The concept of “continuous” intimates that every subject request is validated. Typically post authentication, a user or service is issued a token or cookie – which is known to have interception, man-in-the-middle and malicious re-use issues. To overcome that, token binding has become popular – leveraging a proof of possession approach to prove the device presenting the token is the same as the one that received it post-authentication. The use of MFA on its own does not necessarily mean continuous – unless of course that is being triggered on every request. Unlikely due to usability and performance. The concept of UEBA and monitoring is likely helping to support the identification of misuse continuously – so subtly different. The important aspect will be what happens if the post-authentication event is deemed to be suspicious – what respond and recovery mechanisms are being used?
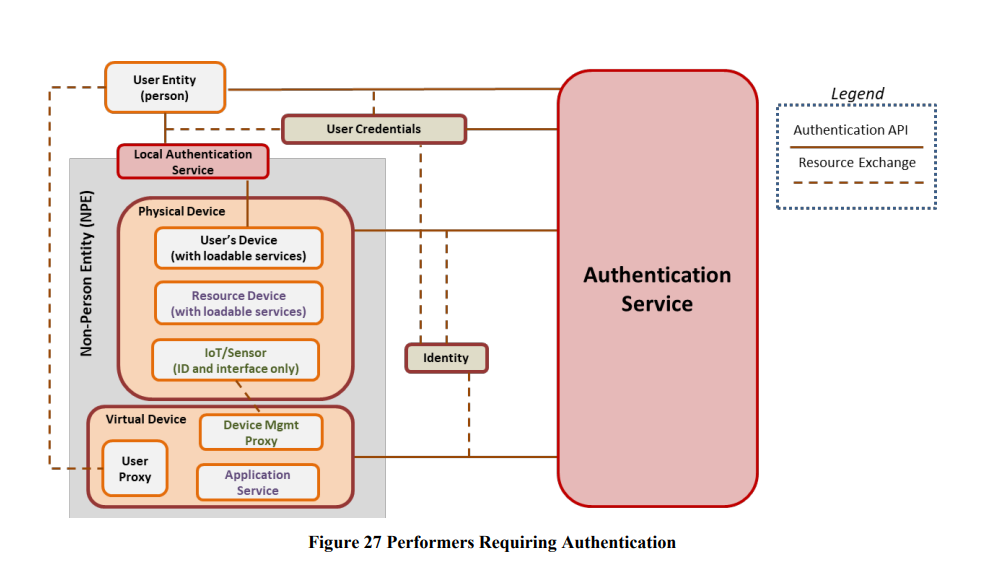
This is a nice image to show the role of NPE. Essentially it is never the user entity that accesses resources – it will be a physical device proxy (laptop, mobile) or indeed a secondary API or service acting on the user’s behalf.
The document articulates “Users will provide credentials that proves the identity of that user and, if validated, is authorized to access the resource..” [page 58]. This is untrue, unless the credential being provided is bound via a biometric proofing process. The use of a credential (cryptographic private key for example) only provides confidence regarding ownership of that credential – not the biographical association with the true identity. Terminology perhaps, but important if identity verification is needed. Identity verification is not the same as authentication.
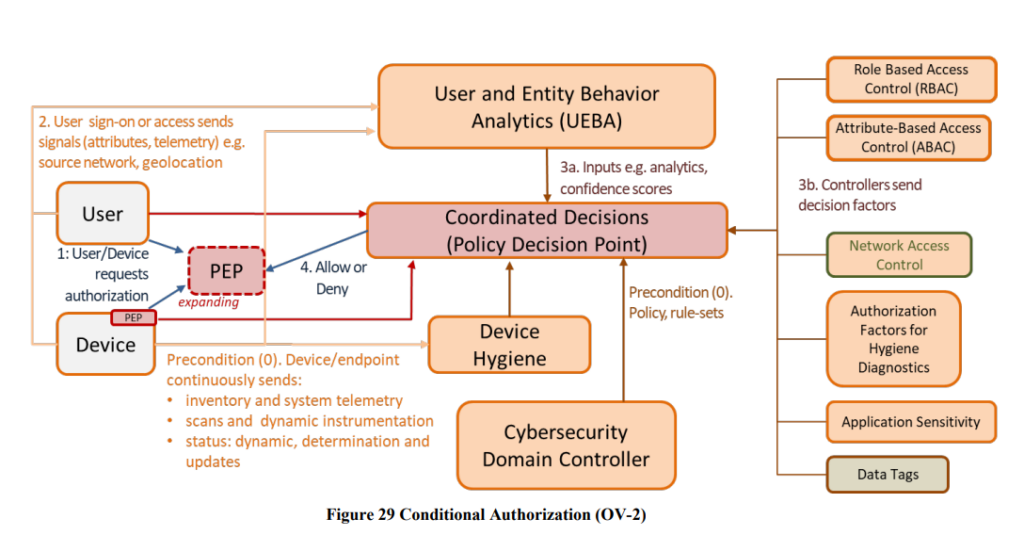
The promotion of the concept that the PDP requires vast amounts of data and signals from multiple sources is good. This additional “context” – from devices, network access control and data tagging is critical in order to respond with fine grained degradation and redaction capabilities.
This is a great and detailed document, with a section regarding maturity mapping and transitioning concepts. The complexity involved will require the use of existing technology investments and architecture designs and the idea that this process is an evolving journey is important.