
| Last Updated | 24 February 2022 |
| Document Tag | tch-research-next-gen-authz |
| Author | simonm@thecyberhut.com |
| Part of Research Product | Next Generation Authorization Technology |
Introduction
Authentication and authorization are often intermingled, interchanged and used at times to describe the same flows and journeys. However they are fundamentally different. Authentication is very much focused on the verification of an entity (typically person based, but not always) and related to a set of challenge / response interactions. The entity is often described by one or two critical attributes – one being a globally unique identifier within the domain of operation – commonly described as the user ID. The second common attribute would be a password. This “single” factor approach to authentication is giving way to multi-factor (or two-factor) authentication – where a combination of something the entity knows, something the entity is and something the entity has is used together.
Authorization on the other hand is very much what happens next – what can the entity do within a system or service once they have been authenticated. This question is often described as access control, which sits under the bigger umbrella of access management.
The Background
There are multiple different authorization models and frameworks. Some standards based, others more architectural in their nature.
Role Based Access Control
Role Based Access Control (RBAC) emerged as the main approach to handle employee based access control in the early 2000’s. Numerous specialist vendors existed in this space such as Vaau, Eurikify, BHold, Sailpoint, Aveksa and Omada. Many are no longer in existence having been acquired and consumed into larger platforms.
RBAC systems grouped users into roles, typically based on a business related characteristic – such as their job code, location or title. The role was then assigned permissions, either directly, or via other roles. The concept being that the role hierarchy acted as an abstraction layer between the user and the permissions within the resource they wished to access. This abstraction was meant to reduce errors with access misalignment, improve efficiency and provide better visibility into the permission allocation process.
Role Types
Roles were typically identified by two buckets: business roles and application or system roles. The business role grouped the user, based on an HR (human resources) owned attribute. The “ownership” aspect pertains to data’s authoritative source. Each attribute in the identity model, should ideally only have one authoritative source to help maintain integrity and attribute quality.
The application role, was then assigned permissions. The permissions are very specific to the application. Permissions within SQL, LDAP, mainframe or a custom application will all be different. The application role would capture the specific “native” nomenclature for the associated permissions. An application role would also be modular and loosely coupled, perhaps being associated to multiple business roles.
Role Mining
A major problem for an RBAC system, was how to create the roles? A simple question, which 20 years ago, was seen as a “computer” problem, often tackled with the early incarnations of machine learning and analytical frameworks.
The “mining” process aimed to do two things: create business roles top down and application roles via bottom up mining.
Top down mining aimed to analyse a group of individuals based on their HR attribute data. For example all users within a particular department or location would be analysed to see which job codes, titles or functions existed. The output would be something like a “Sales Manager” or “IT Support” business role. All users who matched the identified HR pattern of data, would be assigned into the associated role – by the created rules.
Once a business role was created, that could be fed into the second phase – bottom up mining – where the associated per-system permissions could be grouped. This could be slightly more complex, as the grouped permissions would not necessarily map into an easy-to-describe function. This process would also throw up exceptions – where an individual would perhaps have a permission which others in the newly minted business role would not have.
Perhaps they were a supervisor with specific elevated permissions – or maybe it was just a mistake – where permissions had not been removed from a previous job function within the organisation. These exceptions would often slow down the role mining process as business analysis and approval decisions would be needed. In many cases the permission was often removed from the role, but left assigned to the user, mainly as a lack of information regarding the permission-to-business function prevented it from being removed, in case it impacted job productivity.
The success criteria for the role mining process, was to try and capture as many permissions as possible within the role hierarchy – via business and application roles. A value over 80% would be deemed productive.
Role Management
The RBAC infrastructure needs managing. This comes in the form of version control, role governance for the creation and removal of roles, as well as workflows for the association of users to roles. The user to role association process is a business as usual (BAU) activity that is typically semi automated.
The automated nature of user to rule association is often handled by rules. These rules leverage HR based data in order to associate users to the business role. When a new user is onboarded into the HR system, a rule will be triggered to associate the user to a business role. The ruling is essentially an inverse attribute based access control model, following an if this then that style approach. When an HR attribute alters – say for example when a user moves teams – the rule based will trigger again altering their associated roles.
A provisioning system – that connects multiple downstream systems – will be used to alter any user to permission relationships within the target systems.
Subsequent user to role associations would be handled via an access request workflow. This workflow typically consists of approvers – be it line managers or system administrators. The request, approval and execution stages would be all audited for compliance.
Other management tasks that exist, would include the creation and modeling of new roles – which may require things like version control, staged roll out, testing and impact analysis.
Role Explosion
A term often associated with RBAC, is role explosion. This concept refers to the rapid increase in the number of roles to handle a large and growing user population. User to permission exceptions may result in either a vast number of users being directly assigned permissions outside of the roles framework, or individual roles exist with a very small number of users associated with them. The result can be the same number of roles as users, which makes management and governance incredibly difficult.
SoD
Another term synonymous with RBAC is SoD – separation of duties. The SoD concept was amplified by compliance initiatives such as Sarbanes Oxley act of 2002. Whilst specifically focused on the financial services industry, the act was often implemented in other industries. Specifically within the SOx act there is section 404, focused on the assessment of internal control. Here, there is reference to essentially knowing who has access to what systems. The SoD aspect is a control to prevent malicious activity primarily by insiders. The concept being that entire task based workflows, that result in material financial impact, should not be completed by single parties. The tasks should be broken down into component parts, with the permissions and roles provisioned to separate parties – or at least not the same party within the same time period or under contextual constraints. An example being an individual must not be part of the “Accounts Payable” and “Accounts Receivable” roles simultaneously – as that could provide an opportunity for fraud.
The ability to apply SoD controls can apply in two stages. Firstly this can be done dynamically at access request run time, by comparing existing roles to those being requested, with a union calculation being made before access is permitted. Secondly the SoD rules can be run arbitrarily against provisioned data – to periodically check for privilege creep. This is typically known as Identity Audit.
Attribute Based Access Control
Whilst RBAC is still implemented for new and legacy projects alike, more flexible approaches to entitlement management have emerged. One of those concepts is ABAC – attribute based access control.
In ABAC the authorization framework evaluates attributes to decide and ultimately enforce access controls. The attributes could be identity related, or include device, transaction, the object being accessed and so on. The attributes are typically combined into some sort of boolean logic, often handled via policies. ABAC often follows the if-this-then-that approach.
There are typically a few components to think about: the subject, the object being accessed and the actions that the subject wishes to perform against the object.
A more detailed description is available in NIST Special Publication 800-162.
| Subject | JDoe |
| Object | note.txt |
| Action | read |
A policy or decision logic will contain a mixture of attributes that typically must be met before the action is allowed. So for example:
subject.job = manager
subject.location = London
resource.type = document
resource.location = Financial Planning
time.day=[mon-fri]
time.hour=[0900-1800]
action = readMultiple attributes from different sources can be combined, with different levels of logic. In the simple example above, the user can read the file, if they work in London as a manager and it’s essentially office hours.
Architecture Components
There are several components often seen with an ABAC model.
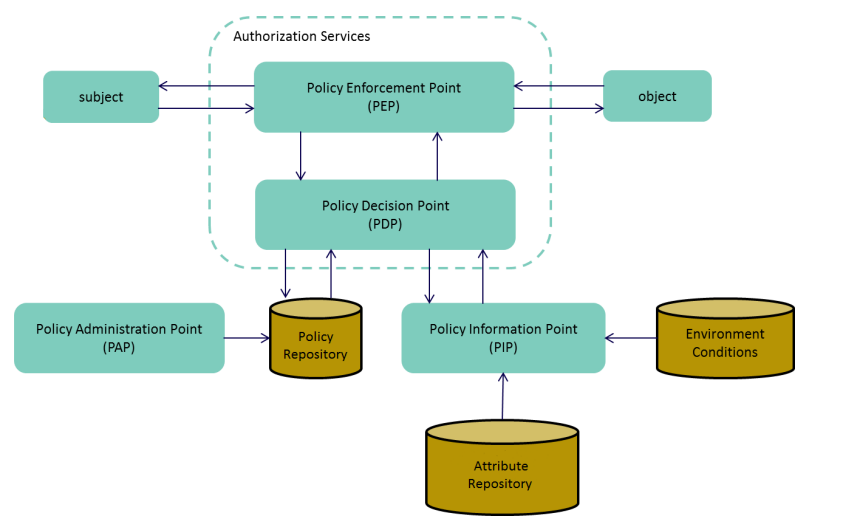
Source: NIST 800-162
PDP
The Policy Decision Point computes the access decision based on the defined logic, rules and policies. The PDP is often seen as being a centralised service.
PEP
The Policy Enforcement Point upholds the PDP’s decision with respect to subject to object relations. The PEP typically intercepts a subject request before engaging with the PDP for guidance. The PEP can be thought of as being distributed and close to the resource being protected.
PAP
The Policy Administration Point is the entry point for rule and policy decision. The PAP should essentially be able to represent the business outcome or function that is being protected, in relay that in a policy format. The PAP may well be part of the PDP.
PIP
A Policy Information Point can provide extra run time or static information to the PDP to help the PDP make more informed decisions.
XACML
The eXtensible Access Control Markup language is an XML based language that is used to represent authorization interactions, often based on the PDP/PEP/PAP/PIP model described above.
It first appeared in 2001, so has a long history and is relatively well known as a concept. It was designed when identity interactions were very much focused on the likes of XML and SAML as a means to describe identity information.
Whilst XACML builds on the PEP/PDP model it is likely it is more “famous” for the rule and policy set approach it contributes to the authorization process. XACML provides a format and set of conditions and operators which application designers can use to describe the authorization rules they need to protect their critical assets.
Version 3.0 is the most recent version, which introduced a JSON profile for XACML as infrastructure started to move away from the comparatively heavy weight of XML into a world of REST and JSON based APIs.
For future reference see the Wikipedia article for a brief introduction and the official OASIS Specification Document on XACML.
OAuth2
OAuth2 is an IETF ratified standard focused on authorization – specifically the delegation aspect of authorization, where an individual wants to share resources they own back to themselves which are being accessed by a third party. For example, allowing photo editing apps to access your Facebook albums. The mechanism underneath may use OAuth2 via the use of time based and scoped access tokens.
There are three main components in the OAuth2 ecosystem – an authorization server, a client app and a resource server, all glued together via the end user, also called the “resource owner”.
This diagram from the IETF RFC 6749 explains this in detail:

Source: RFC 6749
In a standard flow a client application wishes to access data held by the Resource Server (RS). To do this it generates a request which is sent to the Authorization Server (AS) which the Resource Owner (RO) validates – essentially approving or denying the request the requested “scopes” which the client needs to request access. If the RO grants permission, the client receives an access token which it uses to request data or service access from the RS. This access token is time based and will expire and is also “scoped” – meaning it contains just the access that is requested and hopefully nothing more.
Access Token
Access Tokens are “credentials used to access protected resources”. The AS issues the client app with an Access Token (AT) – typically after an intermediate step where an Authorization Code is issued, which itself is exchanged for the AT.
The AT typically comes in two conceptual forms – a stateful token, or a stateless token. A stateful token is an opaque reference that essentially can’t be read by the human eye or the client application. It is presented to the RS, which in turn contacts the AS that issued the token, to determine whether the AT is valid and retrieve information concerning the associated scopes, the expiry time and so on.
A stateless token is issued in the same way, yet the format is a JWT – a JSON Web Token. This essentially means that the token is self contained and can be presented to RS during an access request. The RS then has the ability to verify and validate the presented JWT without necessarily always making a round trip of the issuing AS.
Another concept to be aware of, is the use of Refresh Tokens. An RT is issued alongside an AT – and can be used to request future AT’s when the initial token has expired. Typically an AT has a short life span, whereas an RT considerably longer.
Authorization Service
The AS is a server with a REST/JSON based API that issues tokens and responds to token validation requests from Resource Servers.
Resource Server
The RS is the service that can deliver the data or services that the client app is in need of. The RS accepts Access Tokens, which they validate before granting access to the requesting client.
Client
An app that is essentially requesting access to the RS on behalf of the Resource Owner. This could be a mobile or web application.
For further information the OAuth.net site provides a range of resources and videos.
Emerging Technologies
Over the last 36 months there have been some significant innovations within the authorization space.
Open Policy Agent
Open Policy Agent (OPA) is a Cloud Native Computing Foundation open source project that focuses on decoupling the authorization decision process from the enforcement process.
OPA provides a lightweight decision engine that can be used to help protect modern infrastructure based on microservices, Kubernetes “pods” and other agile DevOps style ecosystems.
It is described as “Policy-based control for cloud native environments”. The concept is a unified declarative framework that allows for the protection of critical assets using a new authorization language, based on ReGo, with the rules and policy data being stored in JSON files.
The OPA instance can be deployed as either a daemon or an embedded library. As a daemon the service runs in a separate process and responds to HTTP requests – returning authorization decision information.
The Cyber Hut’s Technology Test Drive is available here – which provides a more detailed technical overview.
At a basic level, OPA provides both a rule based and persistence approach to policy evaluation.

Integrations are typically focused on the DevOps landscape with the likes of Kubernetes, Envoy and Terraform based configuration support and documentation.
Zanzibar
Zanzibar is Google’s “Consistent, Global Authorization System”. This was described in a Usenix paper in 2019. Google delivers a range of online services and clearly they require an authorization system that is capable of handling millions of requests, users and objects. Zanzibar was their approach to such requirements, especially focused upon the permission storage capability.
A key capability was the ability to centralize permissions. Distributed permission storage is troubled both by data hygiene and freshness issues caused by siloing and also the potential for erroneous evaluation due to lack of visibility during policy evaluation.
Zanzibar had the following goals: correctness, flexibility, low latency, high availability, large scale.
The authorization model is built upon three components: users, relations and objects. An example from the Google landscape could be user “Bob” has relation “owner” to object “Google Doc”. An authorization query that needs responding to, could be “does user “Bob” have “viewer” relations on the Doc”? The Zanzibar ACL contains the tuples between these user, relations and objects.
Another interesting concept is that of “zookies”. A zookie is essentially a timestamp that can be applied to ACL’s, client content or a read event. This allows for a model of consistent based on staleness bounds.

Source: Google Paper on Zanzibar
The above architecture is based on Google’s own implementation of Zanzibar, which has to scale to millions of transactions a second with millions of tuple entries.
There are some interesting open source developments occurring based on Zanzibar. The Zanzibar Academy supported by Auth0 provides a good introduction to the concepts. Auth0 themselves have developed a system called Carta based on Zanzibar. The Keto authorization engine by Ory has also started an implementation. Details can be found here. Another authorization provider called Oso also has an implementation.