Firstly I don’t want to start any more word-wars – whether we should describe external identities as customers or consumers, or whether anything without a person involved is a workload or non-human identity. For simplicity, I used three easy to understand buckets in the title – identity for people, identity for hardware and identity for software.
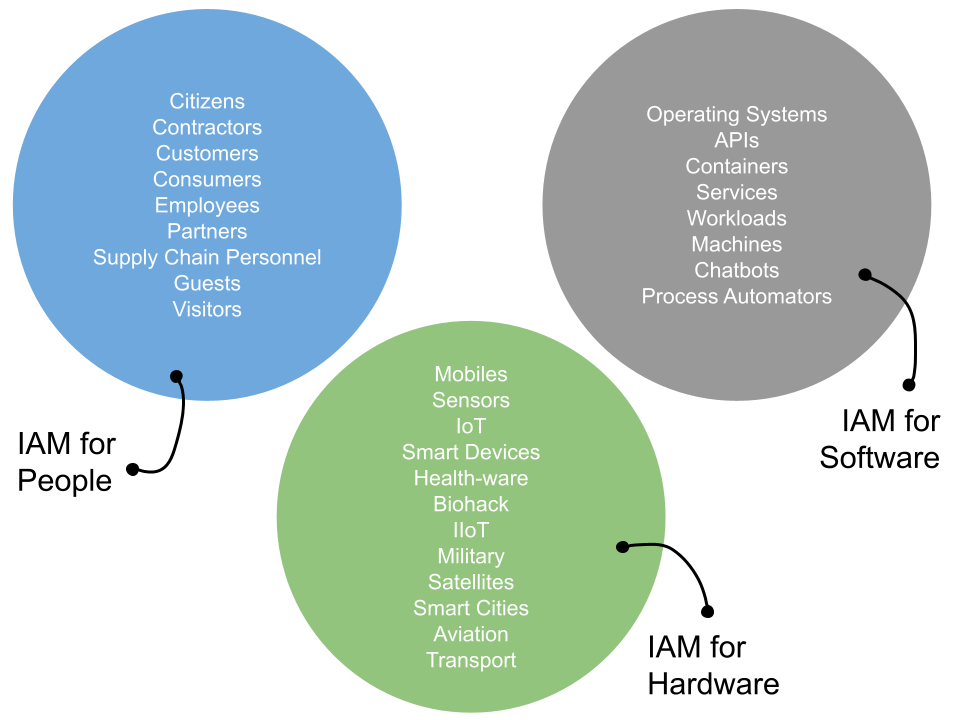
The buckets can be extended, and likely so, but at a high level (and more importantly for those who are not identity specialists) the three should cover most eventualities where identity-centric capabilities are needed. There are some similarities, some differences but each can learn and lean on the other.
B2E – Where The Mould Was Made
Most of our identity-teeth were sharpened by working within the employee and workforce spaces under the generic people bucket. Managing corporate directories, trying to clean permissions, analyse compliance and audit reports and generally reduce manual process and costs while making sure the right staff have the right access at the right time. Operating under the IT, infrastructure and operations teams, B2E IAM was riddled with high consultancy costs, complex integration projects and fragile workflows.
Many of these problems are still being dealt with in 2024, but this early commercial model for identity and access management has provided us with some strong and stable design patterns and an architectural culture.
Firstly we have started to see the IAM problems sitting in two main operational camps – persistent identity data and runtime evaluation.
The former is where we see capabilities such as identity managers (connectors, data sync, transformation), identity governance and administration (permissions management, access request/review, insights, analytics) and storage mechanisms (profile stores, permissions, workflows).
The latter aspect is where we see access management for authentication (MFA, adaptive authentication, sessions, federation) and authorization (policy, enforcement). Now again, I’m simplifying here and there are lots of capabilities and point products that don’t neatly fit into these buckets. The main point to consider, is that the identity does not exist in a vacuum. It is part of a bigger set of functions – with inbound and outbound data links and runtime usage, that when combined provides business value via access to data or completion of an event. There are before and after events – that form part of a life cycle
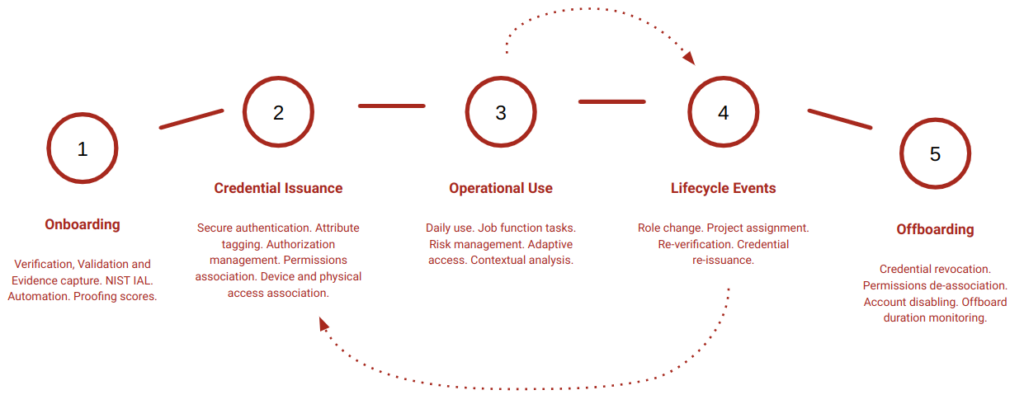
So, again for simplicity, if we consider the workforce identity as part of a bigger set of events that are happening, we can come up with a life cycle like the above. There is a trigger for creation, maybe some proofing and validation, some sort of credential management life cycle (even a password has a life cycle) before the identity is used to do something. At the end, the identity is archived, shelved and removed. The typical joiner–mover–leaver model.
B2C – Where The Mould Was Used and Changed
All well and good. We need software to make a lot of that work, we need business processes (repeatable, adaptive, audited) and we need people to support and manage it. Whilst the details vary, the concept is a powerful one.
Sticking to the people bucket just for a second, I want to take the life cycle approach and apply to our external identity community – so customers, consumers and citizens. I wont get into the differences between B2E and B2C as that is a long and detailed conversation. Needless to say there are many – both functional and non-functional. It is important to note though, that the B2C life cycle is likely more cyclical and repetitive, with perhaps the B2E life cycle being more linear and predictable.
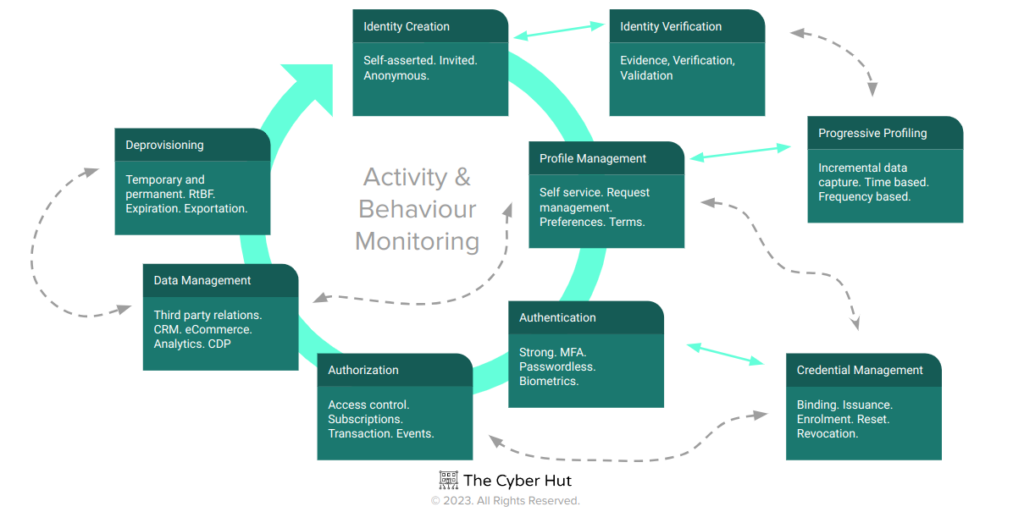
So the steps are clearly different for B2C, but the takeaway would be again that the B2C identity events do not just exist – they are part of a bigger set of processes – which if you like could be partitioned into persistent data and runtime behaviours.
OK – so we have set a little bit of foundation here which should be quite familiar if you have worked on any B2E or B2C project – or part project. Tools operate as part of an integration effort, identity data has lots of tentacles and the runtime use of those identities impacts data and transaction processing.
Life Cycles as a Tool for Future Identity
Why is any of this useful? Well the identity landscape is changing. We’re no longer just confined to managing corporate directories and cleaning up a few excess permissions. B2E is in a transient state. Organisations who are not using cloud service providers or SaaS delivered applications are likely to be very few and far between. Daily data breach reports and incident response write ups, will likely end up with some part of the identity life cycle as being the culprit for adversarial activity. The IAM attack surface is getting larger – more identities, more systems being accessed, more deployment models to support.
The B2C space has to deliver privacy–enabling personalised experiences, that are secure against emerging threats, are usable across a broad-array of global user personalities, whilst simultaneously generating revenue whilst reducing fraud. There are a lot of conflicting goals to contend with there and specialist tools, frameworks and deployment models have emerged to support that.
Life Cycles for Software
The elephant in the room however, is the identity for software bucket. To make both the B2E and B2C worlds work, we need to leverage services, workloads, chatbots, APIs and more. Aka software components that don’t always have a person directly behind the wheel.
The last 12 months have seen an emergence of the workload and non–human identity sector with some significant funding rounds to an array of startups delivering capabilities in this space. The Cyber Hut tracks as part of our IAM2 Map about 8 vendors in this area with a few more to be added – see Aembit, Astrix, Corsha, Natoma, Oasis, SPIRL, Token and trustfour as some examples.

Some compete with each other, some less so, but all should be considered as part of the life cycle set of functions and events as it pertains to the end to end management of workloads and services. We need to have governance, on-boarding (with proofing or attestation), strong authentication that adheres to a strict and repeatable life cycle for credential creation, issuance, revocation and removal as well as runtime access control monitoring and behaviour base lining.
The workload-revolution is not so much a revolution, in the sense it is here today. Even a modest sized organisation will be leveraging an array of identities, accounts and credentials that belong to pieces of code and services. They are likely using hard–coded secrets, over privileged permissions and not tied to any authoritative source for their creation. Service accounts were likely created by a developer who’s general work goal was to build and ship (on time and budget) some software. Repeatability was probably lacking as it pertained to account creation and permissions association and runtime behaviour monitoring is likely to be retrospective and after event.
If the number of workload and non-human identities will surpass those of people-related by 40x or 50x, we also need to take a life cycle approach to their management.
Governance and persistent data management needs to be considered – what are the trigger points for workload identity creation? What data is needed to create a profile? Is a profile actually needed or can an ephemeral set of non-self selected pieces of data (such as process characteristics) be used to define what the service actually is. Do we need an authoritative source? Is it OK for a dev building an app or service to be the starting point for a workload identity?
What about credentials? The bottom-turtle (how to authenticate before we authenticate) style problem on where we should start as it pertains to workload identification and in turn creds issuance is neatly articulated by standards such as SPIFFE. But SPIFFE too is only part of a broader set of end to end events.
The life cycle for workloads is certainly an emerging and evolving concept – but we’re getting close to that being a powerful addition for our identity-centric security arsenal.
The ultimate end goal of identity is to try and deliver assurance (both data and runtime, ie NIST IAL and AAL…) between a subject and an object (with a set of actions in between). We’re evolving from just managing staff in an SAP system to handling complex customer interactions through the to emergence of workloads and services.
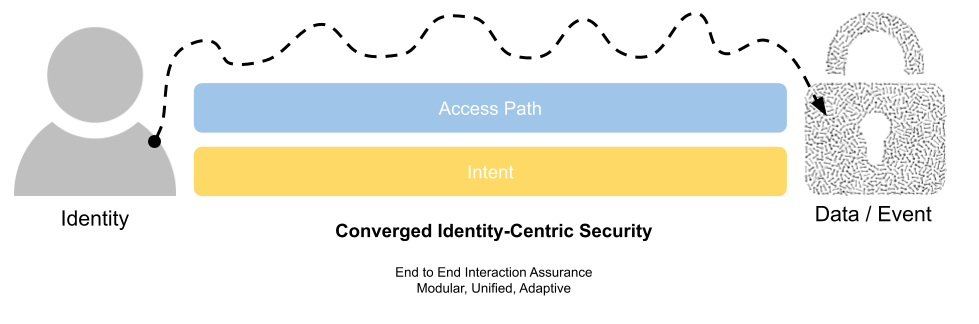
Interaction Assurance is what we want – and that needs to be based on both the access path between the identity and the object as well as the intent. This intent aspect is something I will be writing on further in the coming months as part of the IAM at 2034: A Future Guide to IAM book I am currently working on. To achieve such granular understanding on event processing, we need life cycles for all of our identity types.